
Rocana Releases Rocana Ops 1.5: Real Data Warehousing for IT Operations
- by 7wData
A couple of weeks ago I had the pleasure of meeting Eric Sammer, the co-founder and CTO of Rocana , a very original company in the field of big data and the Hadoop Apache project.
This is a software company that has developed—based on the technologies mentioned—an innovative set of solutions to analyze IT operations data. With what seems to be a good combination of event data warehouse and machine-learning capabilities, its flagship product Rocana Ops captures and analyzes an enormous amount of operations data in order to improve performance, identify existing and emerging problems, and optimize development and operations.
Sammer was kind enough to provide me with a complete briefing of the main and new features from the Rocana Ops solution and the new 1.5 version, launched just recently.
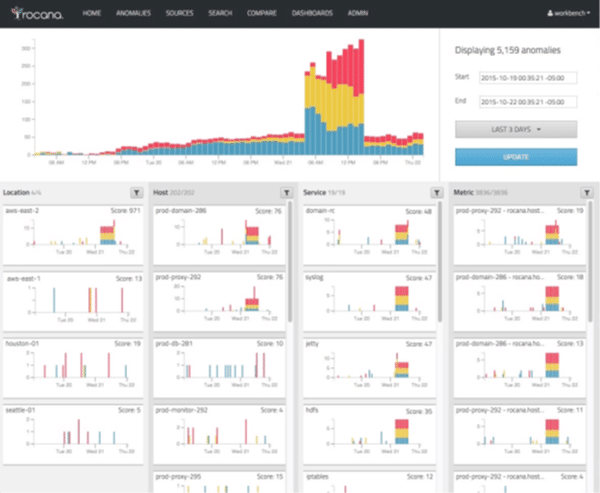
Self-identifying as “the digital transformation company,” Rocana aims to provide enhanced visibility into IT operations by enabling IT departments to collect, store, measure, and analyze large amounts of operations data within a central repository, which can be translated to existing and common IT metrics.
These metrics help to optimize IT operations via analysis and visualization. The solution contains a series of key functional elements along with an event-based data warehouse architecture that, combined with a series of data-collection and advanced-analysis features, provides a centralized infrastructure to perform effective analysis of large amounts of IT operations data.
Once collected, information can be easily understood using Rocana’s pre-built analytics infrastructure and advanced-analytics repository. All of Rocana’s founders have strong roots in the open-source scene, especially the Apache Hadoop project. This is evident in that at its core, the Rocana Ops architecture is a mix of in-house development and various Apache projects. For example, the Hadoop Distributed File System (HDFS) is used for long-term storage and downstream processing, Apache Parquet for supporting columnar storage features, and Apache Kafka for the transport of all data throughout the system.
[Social9_Share class=”s9-widget-wrapper”]
Upcoming Events
Evolving Your Data Architecture for Trustworthy Generative AI
18 April 2024
5 PM CET – 6 PM CET
Read MoreShift Difficult Problems Left with Graph Analysis on Streaming Data
29 April 2024
12 PM ET – 1 PM ET
Read More
