
Why Big Data is in Trouble
- by 7wData
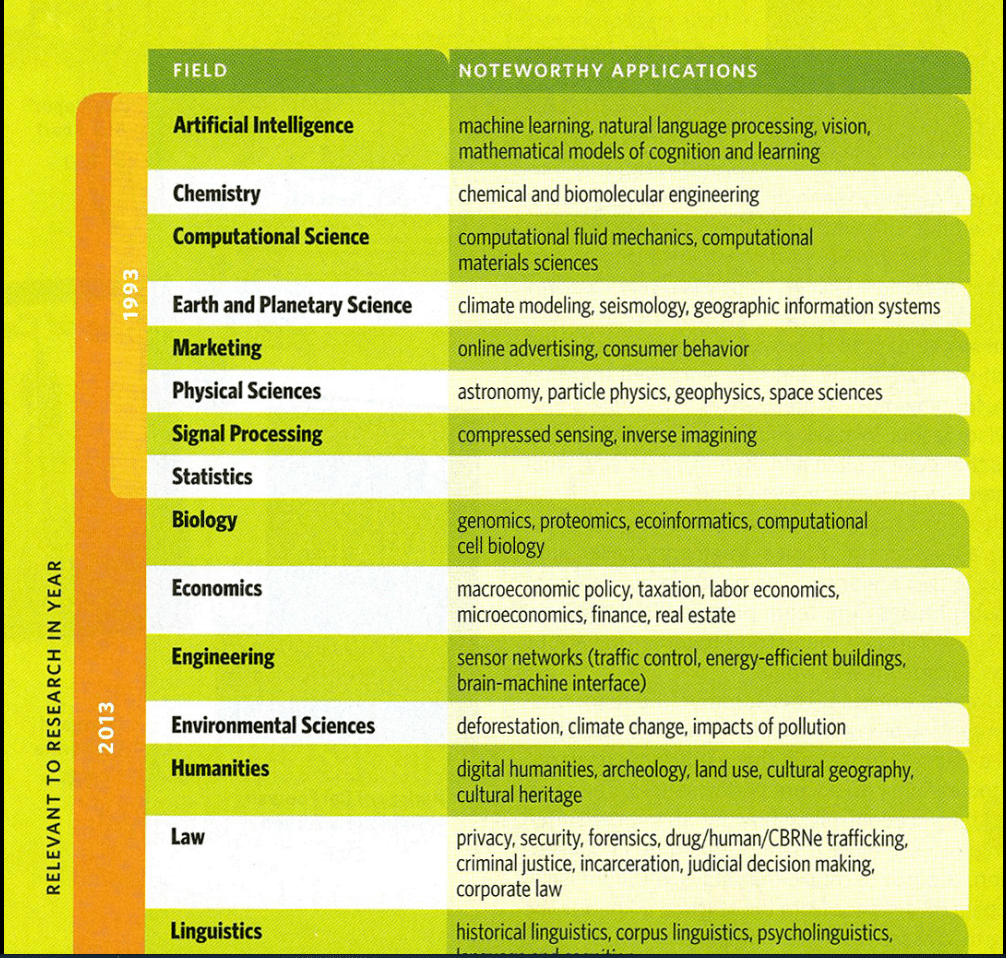
This "classic" (but very topical and certainly relevant) post discusses issues that Big Data can face when it forgets, or ignores, applied statistics. As great of a discussion today as it was 2 years ago.
This year the idea that statistics is important for big data has exploded into the popular media. Here are a few examples, starting with the Lazer et. al paper in Science that got the ball rolling on this idea.
All of these articles warn about issues that statisticians have been thinking about for a very long time: sampling populations, confounders, multiple testing, bias, and overfitting. In the rush to take advantage of the hype around big data, these ideas were ignored or not given sufficient attention.
One reason is that when you actually take the time to do an analysis right, with careful attention to all the sources of variation in the data, it is almost a law that you will have to make smaller claims than you could if you just shoved your data in a Machine Learning algorithm and reported whatever came out the other side.
The prime example in the press is Google Flu trends. Google Flu trends was originally developed as a machine learning algorithm for predicting the number of flu cases based on Google Search Terms. While the underlying data management and machine learning algorithms were correct, a misunderstanding about the uncertainties in the data collection and modeling process have led to highly inaccurate estimates over time. A statistician would have thought carefully about the sampling process, identified time series components to the spatial trend, investigated why the search terms were predictive and tried to understand what the likely reason that Google Flu trends was working.
As we have seen, lack of expertise in statistics has led to fundamental errors in both genomic science and economics. In the first case a team of scientists led by Anil Potti created an algorithm for predicting the response to chemotherapy. This solution was widely praised in both the scientific and popular press. Unfortunately the researchers did not correctly account for all the sources of variation in the data set and had misapplied statistical methods and ignored major data integrity problems. The lead author and the editors who handled this paper didn’t have the necessary statistical expertise, which led to major consequences and cancelled clinical trials.
Similarly, two economists Reinhart and Rogoff, published a paper claiming that GDP growth was slowed by high governmental debt. Later it was discovered that there was an error in an Excel spreadsheet they used to perform the analysis. But more importantly, the choice of weights they used in their regression model were questioned as being unrealistic and leading to dramatically different conclusions than the authors espoused publicly. The primary failing was a lack of sensitivity analysis to data analytic assumptions that any well-trained applied statisticians would have performed.
Statistical thinking has also been conspicuously absent from major public big data efforts so far. Here are some examples:
This year the idea that statistics is important for big data has exploded into the popular media. Here are a few examples, starting with the Lazer et. al paper in Science that got the ball rolling on this idea.
[Social9_Share class=”s9-widget-wrapper”]
Upcoming Events
Evolving Your Data Architecture for Trustworthy Generative AI
18 April 2024
5 PM CET – 6 PM CET
Read MoreShift Difficult Problems Left with Graph Analysis on Streaming Data
29 April 2024
12 PM ET – 1 PM ET
Read More
