
Don’t Drown Yourself With Big Data: Hadoop May Be Your Lifeline
- by 7wData
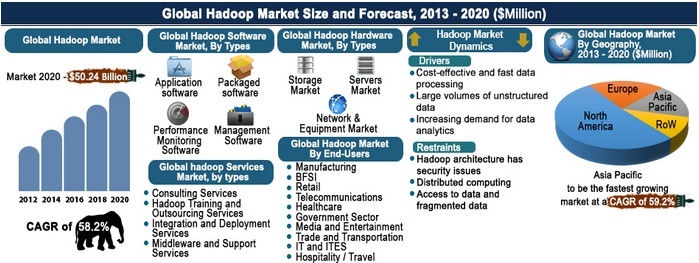
The tremendous growth predicted for the open-source Hadoop architecture for data analysis is driven by the mind-boggling increase in the amount of structured and unstructured data in organizations, and the need for sophisticated, accessible tools to extract business and market intelligence from the data.
The outlook is rosy for Hadoop — the open-source framework designed to facilitate distributed processing of huge data sets. Hadoop is increasingly attractive to organizations because it delivers the benefits of Big Data while avoiding infrastructure expenses.
A recent report from Allied Market Research concludes that the Hadoop market will realize a compound annual growth rate of 58.2 percent from 2013 to 2020, to a total value of $50.2 billion in 2020, compared to $1.5 billion in 2012.
Allied Market Research forecasts a $50.2 billion global market for Hadoop services by the year 2020.
Just how "big" is Big Data? According to IBM, 2.5 quintillion bytes of data are created every day, and 90 percent of all the data in the world was created in the last two years. Realizing the value of this huge information store requires data-analysis tools that are sophisticated enough, cheap enough, and easy enough for companies of all sizes to use.
Many organizations continue to consider their proprietary data too important a resource to store and process off premises. However, cloud services now offer security and availability equivalent to that available for in-house systems. By accessing their databases in the cloud, companies also realize the benefits of affordable and scalable cloud architectures.
The Morpheus database-as-a-service offers the security, high availability, and scalability organizations require for their data-intelligence operations. Performance is maximized through Morpheus's use of 100-percent bare-metal SSD hosting. The service offers ultra-low latency to Amazon Web Services and other peering points and cloud hosting platforms.
The Hadoop architecture distributes both data storage and processing to all nodes on the network. By placing the small program that processes the data in the node with the much larger data sets, there's no need to stream the data to the processing module. The processor splits its logic between a map and a reduce phase.
[Social9_Share class=”s9-widget-wrapper”]
Upcoming Events
Evolving Your Data Architecture for Trustworthy Generative AI
18 April 2024
5 PM CET – 6 PM CET
Read MoreShift Difficult Problems Left with Graph Analysis on Streaming Data
29 April 2024
12 PM ET – 1 PM ET
Read More
