
Finding Needles in a Haystack With Graph Databases and Machine Learning
- by 7wData
You know a technology has reached a tipping point when your kids ask about it. This happened recently when my eighth-grade daughter asked, "What is machine learning and why is it so important?"
Answering her question, I explained how machine learning is part of AI, where we teach machines to reason and learn like human beings. I used the example of fraud detection. In many ways, catching fraud is like finding needles in a haystack — you must sort and make sense of massive amounts of data in order to find your "needles" or, in this case, your fraudsters.
Consider a phone company that has billions of calls occurring in its network on a weekly basis. How can we identify signs of fraudulent activity from a mountain — or haystack — of calls? This is where machine learning comes in.
Of course, my daughter was ready with a solution to the problem: "Why not use a powerful magnet to draw out the needles from the haystack?"
She's right. When it comes to training a machine to spot fraudsters, we need to provide it with a more powerful magnet for drawing them out. Our magnet, in this case, is the ability to identify behaviors and patterns of likely fraudsters. Using this, a machine is more adept at recognizing suspicious phone call patterns and is able to separate them from the billions of calls made by regular people who comprise our haystack of data.
Let's use this example to consider current approaches for identifying fraudsters based on machine learning. Supervised machine learning algorithms need training data — in this case, phone calls identified as calls from confirmed fraudsters. There are two problems with the current approach, including both the quantity and of training data.
Confirmed fraudulent activity in phone networks currently constitutes less than 0.01% of total call volume. So, the volume or the quantity of training data with confirmed fraud activity is tiny. Having a small quantity of training data, in turn, results in poor accuracy for the machine learning algorithms.
Features or attributes for finding a fraudster are based on simple analyses. In this case, they include calling history of particular phones to other phones that may be in or out of the network, the age of a pre-paid SIM card, the percentage of one-directional calls made (cases where the call recipient did not return a phone call), and the percentage of rejected calls.These simplistic features tend to result in a lot of false positives. It's no wonder when you consider how, in addition to a fraudster, these features may also fit the behavior of a salesperson or a prankster!
A large mobile operator uses TigerGraph, the next-generation graph database with real-time deep link analytics, to address the deficiencies of current approaches for training machine learning algorithms. The solution analyzes over ten billion calls for 460 million mobile phones and generates 118 features for each mobile phone. These are based on deeper analysis of calling history and go beyond immediate recipients for calls.
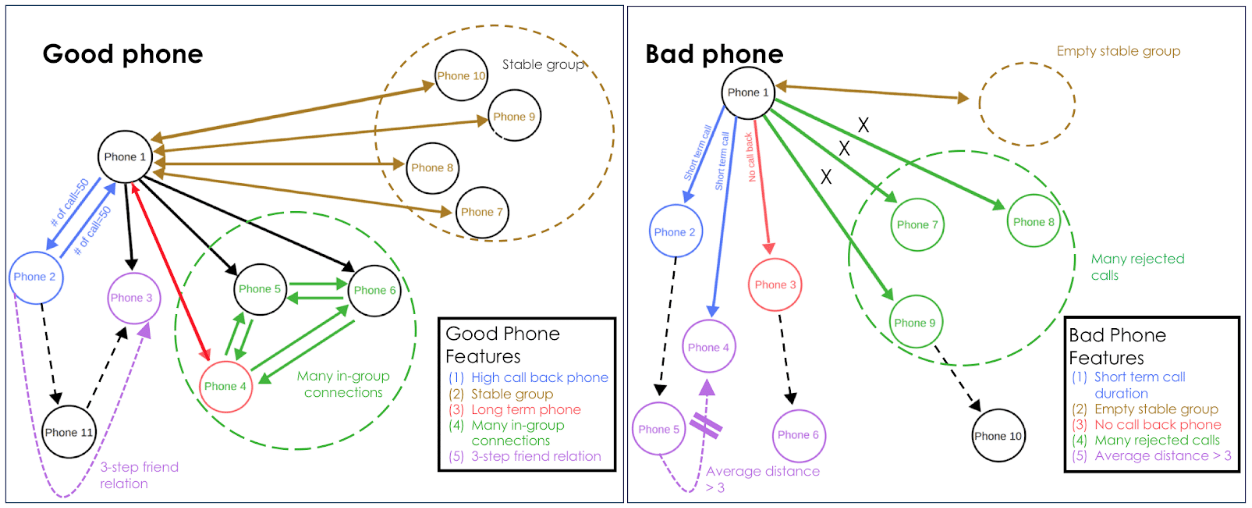
The diagram below illustrates how the graph database identifies a phone as a "good" or a "bad" phone. A bad phone requires further investigation to determine whether it belongs to a fraudster.
A customer with a good phone calls other subscribers, and the majority of their calls are returned. This helps to indicate familiarity or trusted relationships between the users. A good phone also regularly calls a set of others phones — say, every week or month — and this group of phones is fairly stable over a period of time ("stable group").
Another feature indicating good phone behavior is when a phone calls another that has been in the network for many months or years and receives calls back. We also see a high number of calls between the good phone, the long-term phone contact, and other phones within a network calling both these numbers frequently. This indicates many in-group connections for our good phone.
[Social9_Share class=”s9-widget-wrapper”]
Upcoming Events
From Text to Value: Pairing Text Analytics and Generative AI
21 May 2024
5 PM CET – 6 PM CET
Read More