
Benchmarks to prove you need an analytical database for Big Data
- by 7wData
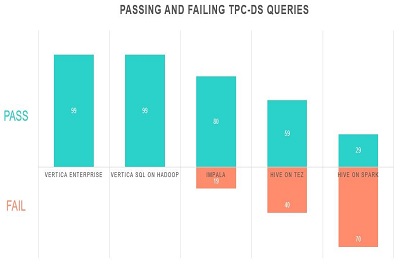
When it comes to big data, it’s important to ask “What’s next?” Sure, users find lower licensing costs when storing data in Hadoop—although they often do pay for subscriptions. Storing data efficiently in a cluster of nodes is the table stakes for data management today. However, it’s important to remember what happens next. The next step is often about performing analytics on the data as it sits in the Hadoop cluster. When it comes to this, our internal benchmarking testing reveals limitations of the Apache Hadoop platform.
We set up a 5-node cluster of Hewlett Packard Enterprise DL380 ProLiant servers. We created 3 TBs of data in ORC, Parquet, and our own ROS format. Then, we put the TPC-DS benchmarks to the test with Vertica, Impala, Hive on Tez, and even Apache Spark. We took a look at CDH 5.7.1 and Impala 2.5.0 and HDP 2.4.2 Hawq 2.0 in comparison to Vertica.
We first took note of whether all the benchmarks would run. This becomes important when you’re thinking about the analytical workload. Do you plan to perform any complex analytics? In our benchmarks, Vertica completed 100% of the TPC-DS benchmarks while all others could not.
Initially, the results were very poor for the Hadoop-based solutions until we found some rewritten queries on github for some tools.
For example, if you want to perform time series analytics and the queries are not available, how much will it cost you to engineer a solution? How many lines of code will you have to write and maintain to accomplish the desired analytics.
[Social9_Share class=”s9-widget-wrapper”]
Upcoming Events
From Text to Value: Pairing Text Analytics and Generative AI
21 May 2024
5 PM CET – 6 PM CET
Read More