
Data Lake 3.0, Part IV: Cutting Storage Overhead in Half With HDFS Erasure Coding
- by 7wData
Thank you for reading our Data Lake 3.0 series! In Part I of the series, we introduced what a Data Lake 3.0 is. In Part II of the series, we talked about how a multi-colored YARN will play a critical role in building a successful Data Lake 3.0. In Part III of the series, we looked under the hood and demonstrated a Deep Learning framework (TensorFlow) assembly on Apache Hadoop YARN. In this blog, we will talk about how to create a Big Data archive to power the Data Lake 3.0 storage.
Apache Hadoop provides a cheap and effective way to store vast amounts of data on commodity hardware via the Hadoop Distributed File System (HDFS). Robust features, such as fault-tolerance and data locality, are enabled by the default 3x replication factor. The simplicity of this replication policy comes at the cost of a 200% storage overhead. As organizations continue to onboard more data and workloads to Hadoop, the storage overhead has become more burdensome, particularly with data sets that are infrequently accessed. This has left many organizations with the dilemma of either expanding their clusters to keep lightly used data accessible or archiving it off-cluster.
In this blog, we will introduce HDFS Erasure Coding as a solution to this quandary, enabling efficient storage (< 50% overhead) and thus effectively providing archival storage within a cluster while keeping the data accessible for analytics and maintaining the same fault tolerant properties of 3x replication.
Heterogeneous storage was introduced in Hadoop 2.3, enabling cluster disks to be labeled according to a set of predefined tiers (RAM_DISK, SSD, DISK, and ARCHIVE). For example, standard data nodes (i.e., 12 x 2TB) would have volumes labeled as “DISK” whereas the drives in a more storage-dense and compute-light node (60 x 4TB) would be labeled as “ARCHIVE”. This enabled a single cluster to be backed by data nodes that were, potentially, a collection of heterogeneous storage devices.
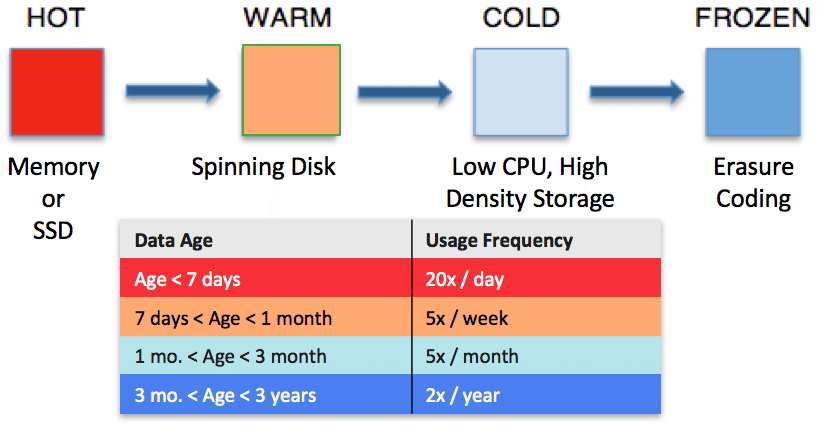
Heterogeneous storage laid the foundation to support data movement among tiers based on access patterns and “data temperature.” Hadoop 2.6 introduced storage policies that assign block replicas based on predefined temperatures. For example, all data is considered HOT by default and thus all replicas are stored in the DISK tier. On the other hand, data that is labeled WARM will have one replica in the DISK tier and the other replicas moved to the ARCHIVE tier. An HDFS directory can flow between tiers by assigning the directory a new tier and then invoking the HDFS Mover which reassigns replicas appropriately.
Figure 1: An example of how data would move through storage tiers as its temperature changes.
Heterogeneous storage tiers and storage policies enable organizations to more effectively control the growth of storage capacity independent of computational resources. However, the storage tiers of Hadoop 2.x still leverage replicas for redundancy and thus come with the inherent storage overhead. The next logical step is to introduce an additional tier that encompasses data that is “sealed” and can be encoded via erasure coding to achieve deep, archival storage on-cluster.
Erasure codes (EC), or error correcting codes, are a process for encoding a message with additional data such that a portion of the encoded message can be lost or corrupted and the original message can still be recovered. More specifically, if a block of data contains k bits of data, then we can encode it into a longer message of size n such that the original message can be recovered from a subset of the n bits of data.
Figure 2: An illustration of the XOR encoding and recovery process in a RAID-5 array with 3 drives.
A simple example of error-correcting codes is the XOR parity (used in a RAID-5 array). This RAID configuration will stripe blocks of data across an array of physical disks where one of the disks is dedicated to storing the parity.
[Social9_Share class=”s9-widget-wrapper”]
Upcoming Events
Shift Difficult Problems Left with Graph Analysis on Streaming Data
29 April 2024
12 PM ET – 1 PM ET
Read MoreCategories
You Might Be Interested In
Real-Time Data Processing Requires More Agile Data Pipelines
30 Apr, 2022Healthy data pipelines are necessary to ensure data is integrated and processed in the sequence required to generate business intelligence. …
6 Signs Your Enterprise BI Software Is Below Par
15 Aug, 2017What makes a BI solution enterprise-ready? Or, by the same token, what warning signs tell you immediately that your BI …
Aylien launches news analysis API powered by its deep learning tech
26 Apr, 2016Text analysis startup Aylien, which uses deep learning and NLP algorithms to parse text and extract intel from documents for its customers, has launched a …
Recent Jobs

Do You Want to Share Your Story?
Bring your insights on Data, Visualization, Innovation or Business Agility to our community. Let them learn from your experience.
Privacy Overview
Get the 3 STEPS
To Drive Analytics Adoption
And manage change
