
Introducing a Graph-based Semantic Layer in Enterprises
- by 7wData
Things, not Strings Entity-centric views on enterprise Information and all kinds of data sources provide means to get a more meaningful picture about all sorts of business objects. This method of information processing is as relevant to customers, citizens, or patients as it is to knowledge workers like lawyers, doctors, or researchers. People actually do not search for documents, but rather for facts and other chunks of information to bundle them up to provide answers to concrete questions.
Strings, or names for things are not the same as the things they refer to. Still, those two aspects of an entity get mixed up regularly to nurture the Babylonian language confusion. Any search term can refer to different things, therefore also Google has rolled out its own Knowledge Graph to help organizing information on the web at a large scale.
Semantic graphs can build the backbone of any information architecture, not only on the web. They can enable entity-centric views also on enterprise information and data. Such graphs of things contain information about business objects (such as products, suppliers, employees, locations, research topics, …), their different names, and relations to each other. Information about entities can be found in structured (relational databases), semi-structured (XML), and unstructured (text) data objects. Nevertheless, people are not interested in containers but in entities themselves, so they need to be extracted and organized in a reasonable way.
Machines and algorithms make use of semantic graphs to retrieve not only simply the objects themselves but also the relations that can be found between the business objects, even if they are not explicitly stated. As a result, ‘knowledge lenses’ are delivered that help users to better understand the underlying meaning of business objects when put into a specific context.
Personalization of information The ability to take a view on entities or business objects in different ways when put into various contexts is key for many knowledge workers. For example, drugs have regulatory aspects, a therapeutical character, and some other meaning to product managers or sales people. One can benefit quickly when only confronted with those aspects of an entity that are really relevant in a given situation. This rather personalized information processing has heavy demand for a semantic layer on top of the data layer, especially when information is stored in various forms and when scattered around different repositories.
Understanding and modelling the meaning of content assets and of interest profiles of users are based on the very same methodology. In both cases, semantic graphs are used, and also the linking of various types of business objects works the same way.
Recommender engines based on semantic graphs can link similar contents or documents that are related to each other in a highly precise manner. The same algorithms help to link users to content assets or products. This approach is the basis for ‘push-services’ that try to ‘understand’ users’ needs in a highly sophisticated way.
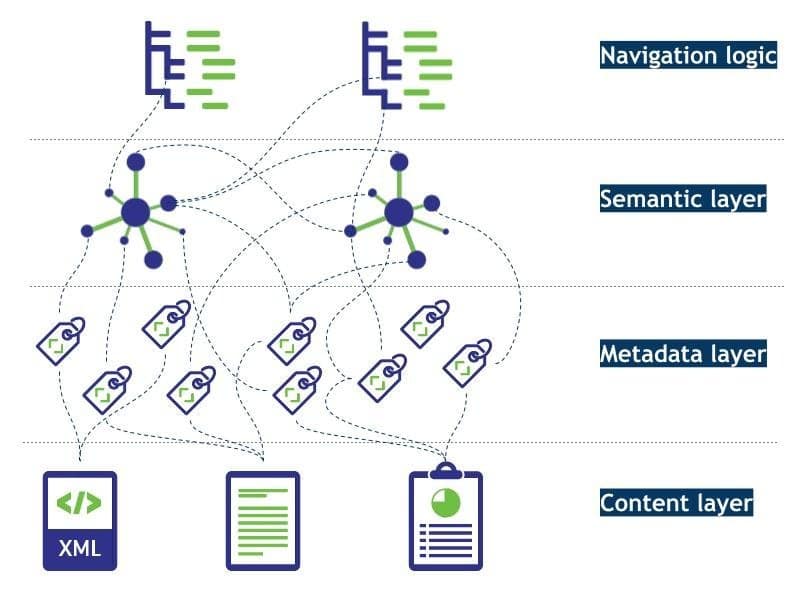
‘Not only MetaData’ Architecture Together with the data and content layer and its corresponding metadata, this approach unfolds into a four-layered information architecture as depicted here.
Following the NoSQL paradigm, which is about ‘Not only SQL’, one could call this content architecture ‘Not only Metadata’, thus ‘NoMeDa’ architecture. It stresses the importance of the semantic layer on top of all kinds of data. Semantics is no longer buried in data silos but rather linked to the metadata of the underlying data assets. Therefore it helps to ‘harmonize’ different metadata schemes and various vocabularies. It makes the Semantics of metadata, and of data in general, explicitly available. While metadata most often is stored per data source, and therefore not linked to each other, the semantic layer is no longer embedded in databases.
[Social9_Share class=”s9-widget-wrapper”]
Upcoming Events
Shift Difficult Problems Left with Graph Analysis on Streaming Data
29 April 2024
12 PM ET – 1 PM ET
Read MoreCategories
You Might Be Interested In
How to Answer the “Why” Behind a Data Strategy?
29 Jun, 2020Critical success factors behind a modern analytics landscape lies from the fact that it is not restricted to technical excellence …
How Data for Good Can Be Used to Improve Our World
2 Jul, 2020I’m determined to promote data for good. Why? As an inherently on-demand generation, we constantly hear about the data imperative: …
How New Developments in Big Data Show us where B2B Marketers Are Headed Next
10 Oct, 2016Big Data is often dismissed as a buzzword, but the simple truth is that better B2B marketing data is continually …
Recent Jobs

Do You Want to Share Your Story?
Bring your insights on Data, Visualization, Innovation or Business Agility to our community. Let them learn from your experience.
Privacy Overview
Get the 3 STEPS
To Drive Analytics Adoption
And manage change
