
The Next Wave of Deep Learning Architectures
- by 7wData
Intel has planted some solid stakes in the ground for the future of deep learning over the last month with its acquisition of deep learning chip startup, Nervana Systems, and most recently, mobile and embedded machine learning company, Movidius.
These new pieces will snap into Intel’s still-forming puzzle for capturing the supposed billion-plus dollar market ahead for deep learning, which is complemented by its own Knights Mill effort and software optimization work on machine learning codes and tooling. At the same time, just down the coast, Nvidia is firming up the market for its own GPU training and inference chips as well as its own hardware outfitted with the latest Pascal GPUs and requisite deep learning libraries.
While Intel’s efforts have garnered significant headlines recently with that surprising pair of acquisitions, a move which is pushing Nvidia harderto demonstrate GPU acceleration (thus far the dominant compute engine for model training) for deep learning, they still have some work to do to capture mindshare for this emerging market. Further complicating this is the fact that the last two years have brought a number of newcomers to the field—deep learning chip upstarts touting the idea that general purpose architectures (including GPUs) cannot compare to a low precision, fixed point, specialized approach. In fact, we could be moving into a “Cambrian explosion” for computer architecture — one that is brought about by the new requirements of deep learning. Assuming, of course, there are really enough applications and users in a short enough window that the chip startups don’t fall over waiting for their big bang.
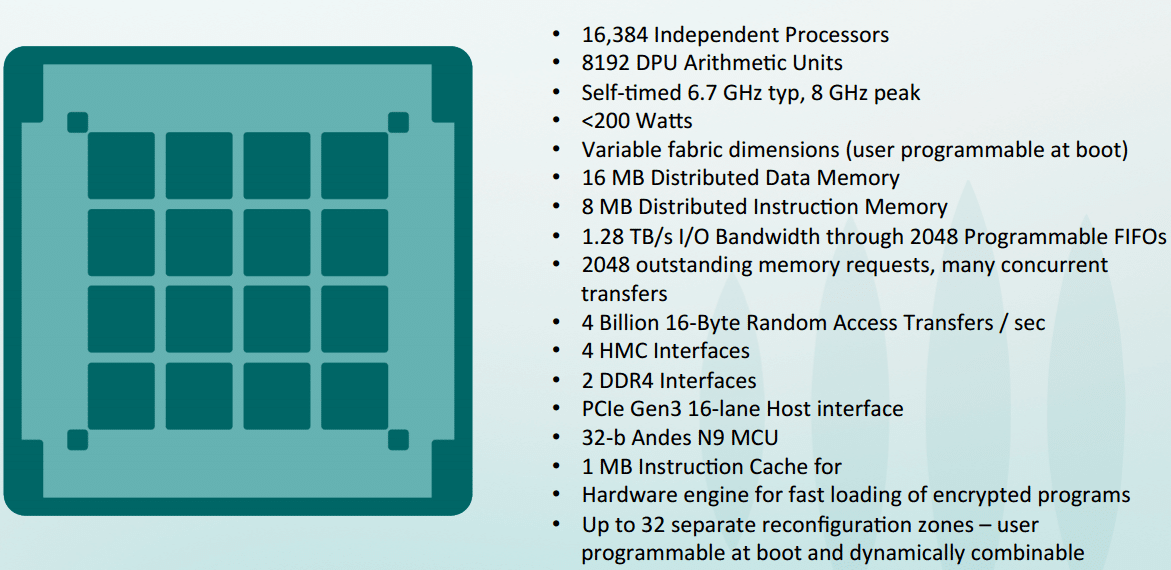
Among the upstarts that fit the specialization bill for deep learning is Wave Computing, which in many ways could have served as a suitable acquisition target for an Intel (or other another party) over Nervana Systems. Although the execution and technology are different from Nervana, the fundamental belief that it is practical to do large-scale deep learning training on ultra-low precision hardware with low-level stochastic rounding and other techniques is the same. And while the company’s Jin Kim tells The Next Platform they see high value in their own technology for companies like Intel, the Nervana acquisition is actually a positive element for the field overall because it proves that there is a need for non-general purpose hardware for such a market.
One could make the argument that Intel was just as interested in Nervana for its Neon software framework as it was for the chip, but Wave Computing’s Kim says that there is another unmet need that has companies scrambling. “There are development boards and accelerator boards, but as we talk to people in the field they want a single system that is designed for the specific needs of deep learning.” Of course, something like this already exists in Nvidia’s DGX-1 appliance, which is outfitted with Pascal-generation GPUsand has all software ready to roll for both training and inference. However, Kim says that they have mastered both the hardware and software and can (in theory—they don’t yet have a DGX-1 appliance on hand) beat out Pascal with lower thermals and far faster training times. More on that in a moment; for now, however, the key point is this is one of the first systems to take on deep learning aside from DGX-1, but of course, it is based on a novel architecture.
The Wave Computing approach is based on a dataflow architecture via their DPU processing elements. Like Nervana, Wave has a highly scalable shared memory architecture (with hybrid memory cube or HMC) at the core. “We are both taking the perspective that there are some familiar characteristics of deep learning compute workloads—this means we can take advantage of the fact that these algorithms are resilient to noise and errors. That, coupled with data parallelism and the opportunity to reuse data are just a few things that give this an advantage over general purpose hardware.
[Social9_Share class=”s9-widget-wrapper”]
Upcoming Events
Shift Difficult Problems Left with Graph Analysis on Streaming Data
29 April 2024
12 PM ET – 1 PM ET
Read MoreCategories
Tags
You Might Be Interested In
An Open Letter to Public Data
12 Jul, 2016How I love that you’re available to me, that in theory, I can answer the questions to life, the universe, …
How Industrial IoT enables the factory of the future
19 Sep, 2018Trillion-dollar projections on the expanding size of the market are urging companies to capitalize on the Industrial IoT [IIoT]. For …
10 Dataviz Tools To Enhance Data Science
15 Dec, 2016Data visualizations can help business users understand analytics insights and actually see the reasons why certain recommendations make the most …
Recent Jobs

Do You Want to Share Your Story?
Bring your insights on Data, Visualization, Innovation or Business Agility to our community. Let them learn from your experience.
Privacy Overview
Get the 3 STEPS
To Drive Analytics Adoption
And manage change
