
Top Streaming Technologies for Data Lakes and Real-Time Data
- by 7wData
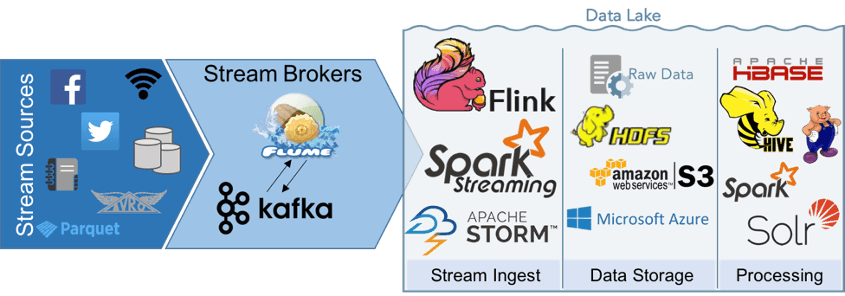
More than ever, streaming technologies are at the forefront of the Hadoop ecosystem. As the prevalence and volume of real-time data continues to increase, the velocity of development and change in technology will likely do the same. However, as the number and complexity of streaming technologies grow, consumers of Hadoop must face an increasing number of choices with increasingly blurred delineation of functionality.
While it would be hard to encompass all information about streaming ingest in one page (or even one book), this post is meant to provide a basic overview of the ways in which various Hadoop technologies fit into the data lake and provide a jumping-off point for further exploration. Notably, there are many, many more technologies than are shown in the diagram below -- these are just a few of the most common.
The first point to make when considering streaming in the data lake is that although many of the available technologies are incredibly flexible and can be used in multiple contexts, a well-executed data lake provides strict rules and processes around ingestion. For example, Kafka and Flume both allow connections directly into Hive and HBase, and Spark can ingest and process data without ever writing to disk. This functionality is robust, but also compromises the original, unaltered data, which is a main principle of data lake architecture. Because of this, we generally restrict the ways in which data flows through the system. Data must be ingested, written to a raw landing zone where it can be held, and copied to another zone for processing and enrichment.
Flume and Kafka are the two most well-established messaging systems in use today. An extremely simple analysis of these products is below.
Kafka is the newer of the two technologies but is quickly gaining traction as a robust, scalable and fault-tolerant messaging system. Whereas Flume can be thought of as a pipe between two points, Kafka is more of a broadcast, making data “topics” available to any subscribers who have permission to listen in. This makes Kafka, as a whole, more scalable than Flume, and also provides mechanisms for fault tolerance and redundancy of data. If one Kafka agent goes down, another will re-broadcast the topic. Where Kafka does fall short is in commercial support. Currently, Cloudera includes Kafka, but MapR and Hortonworks do not. Additionally, Kafka does not include built-in connectors to other Hadoop products. Some have been pre-written, but in general, you can’t expect the same level of “out-of-the-box” connectivity as Flume.
Flume has historically been the only choice for streaming ingest and as such, is well-established in the Hadoop ecosystem and is supported in all commercial Hadoop distributions. For large, enterprise-wide Hadoop deployments, this is an attractive, or even essential feature and may be reason enough to choose it. Despite its age, Flume has largely stayed fresh with emerging Hadoop technologies. Flume is a push-to-client system and operates between two endpoints rather than as a broadcast for any consumer to plug into.
[Social9_Share class=”s9-widget-wrapper”]
Upcoming Events
From Text to Value: Pairing Text Analytics and Generative AI
21 May 2024
5 PM CET – 6 PM CET
Read More