
Open Sourcing SparkADMM: a Massively-parallel Framework for Solving Big Data Problems
- by 7wData
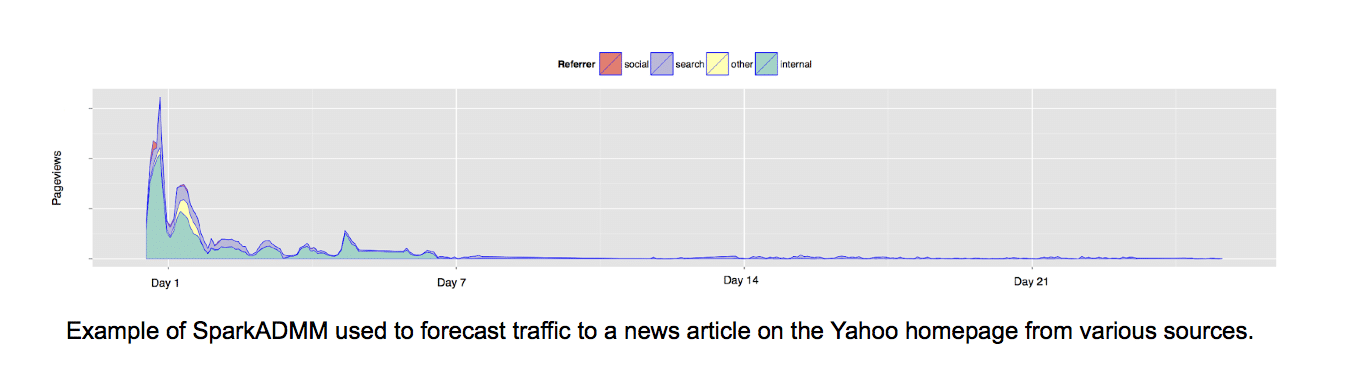
Training machine learning models over massive amounts of data is a cornerstone of many data analytics tasks. Usually this involves solving large optimization problems involving millions of optimization variables and constraints. Doing so over a parallel platform, like Spark or Hadoop, is crucial to making such computations scalable.
It is not always obvious how to solve large optimization problems in parallel. ADMM, which stands for the Alternating Directions Method of Multipliers, is a popular parallel optimization technique that provides a methodology for doing so. It permits the parallelization of a broad array of several important machine learning tasks, such as regression and classification, in a massively parallel fashion. For example, to train a classifier using ADMM over a very large dataset, a developer first splits the dataset and partitions it across multiple machines. A classifier is trained on each machine, based on the locally-stored portion of the dataset. Then, a global classifier learned from the entire dataset is extracted through consensus; ADMM averages out these classifiers and repeats the process through several iterations, forcing the local computations to be closer to the consensus value each time. This way, after several iterations, ADMM constructs a “consensus” classifier, which provably fits the entire dataset.
ADMM’s strength lies in its generality: it gives a template on how to take any serial machine learning algorithm designed to operate locally on a single dataset, and parallelize its execution over thousands of machines.
[Social9_Share class=”s9-widget-wrapper”]
Upcoming Events
From Text to Value: Pairing Text Analytics and Generative AI
21 May 2024
5 PM CET – 6 PM CET
Read More